Förtroendeintervall
Vad är förtroendeintervall:
Det är en uppskattning av ett intervall som används i statistiken, som innehåller en befolkningsparameter. Denna okända populationparameter hittas genom en provmodell beräknad från de insamlade data .
Exempel: Medelvärdet av ett samlat samlat x-värde kan eller kanske inte matcha det sanna populationmedlet μ. För detta är det möjligt att överväga en rad provmedel där den här populationen kan innehålla. Ju längre detta intervall desto större sannolikheten för detta uppstår.
Förtroendeintervallet uttrycks i procent, betecknad av konfidensnivå, med 90%, 95% och 99% som den mest angivna. I bilden nedan har vi till exempel ett 90% konfidensintervall mellan dess övre och nedre gränser (a och -a ).
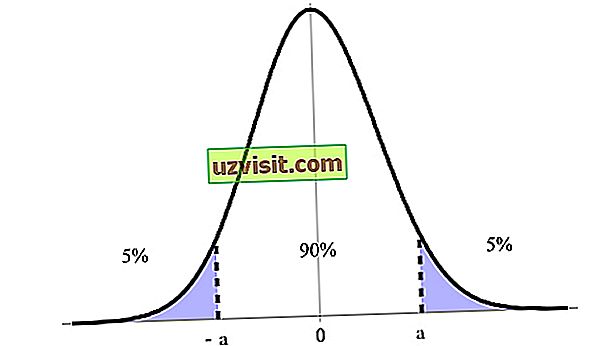
Förtroendeintervallet är ett av de viktigaste begreppen inom hypotesprovning i statistik, eftersom den används som ett mått på osäkerhet. Termen introducerades av polsk matematiker och statistiker Jerzy Neyman 1937.
Vad är relevansen av ett förtroendeintervall?
Förtroendeintervallet är viktigt för att ange marginalen för osäkerhet (eller oriktighet) mot en beräkning som gjorts. Denna beräkning använder studieprovet för att uppskatta den verkliga storleken på resultatet i källpopulationen.
Beräkningen av ett konfidensintervall är en strategi som tar hänsyn till felprovtagning. Storleken på resultatet av din studie och ditt konfidensintervall karakteriserar de antagna värdena för den ursprungliga befolkningen.
Ju smalare konfidensintervallet är desto större är sannolikheten för att procentandelen av studiepopulationen representerar det verkliga antalet källpopulationer, vilket ger större säkerhet om resultatet av studieobjektet.
Hur tolkar du ett förtroendeintervall?
Den korrekta tolkningen av konfidensintervallet är förmodligen den mest utmanande aspekten av detta statistiska koncept. Ett exempel på den vanligaste tolkningen av konceptet är följande:
Det finns en 95% sannolikhet att det sanna värdet av populationsparametern (t.ex. genomsnittet) i framtiden faller inom intervallet X (nedre gräns) och Y (övre gräns).
Således tolkas konfidensintervallet enligt följande: det är 95% säker på att intervallet mellan X (nedre gränsen) och Y (övre gränsen) innehåller det sanna värdet av populationsparametern.
Det skulle vara helt fel att ange att: det finns 95% sannolikhet att intervallet mellan X (nedre gränsen) och Y (övre gränsen) innehåller det verkliga värdet av populationsparametern.
Ovanstående uttalande är den vanligaste missuppfattningen om konfidensintervallet. När det statistiska intervallet har beräknats kan det bara innehålla populationparametern eller inte.
Intervallen kan emellertid variera mellan prover, medan den sanna populationsparametern är densamma oberoende av provet.
Därför kan konfidensintervallförtroendeuppsättningen endast göras i det fall där konfidensintervallet omberäknas för antalet prover.
Stegen att beräkna konfidensintervallet
Området beräknas enligt följande steg:
- Samla provdata: n ;
- Beräkna provet medel x x;
- Bestäm om en populationens standardavvikelse ( σ ) är känd eller okänd;
- Om en standardavvikelse för befolkningen är känd kan en zpunkt användas för motsvarande konfidensnivå.
- Om en standardavvikelse för befolkningen är okänd kan vi använda en statistik t för motsvarande konfidensnivå.
- Sålunda hittas de lägre och övre gränserna för konfidensintervallet med användning av följande formler:
a) Standardavvikelse för en känd population :
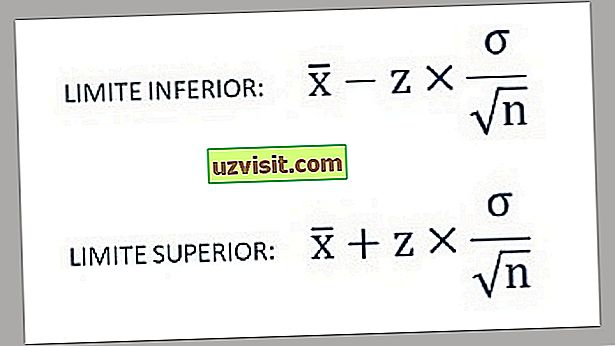
Formel för beräkning av standardavvikelsen hos en känd population.
b) Standardavvikelse för en okänd population :

Formel för beräkning av standardavvikelsen hos en okänd befolkning.
Praktiskt exempel på ett konfidensintervall
En klinisk studie utvärderade sambandet mellan närvaron av astma och risken för att utveckla obstruktiv sömnapné hos vuxna.
Vissa vuxna rekryterades slumpmässigt från en lista över statstjänstemän som skulle följas i fyra år.
Deltagare med astma, jämfört med dem utan, hade större risk att utveckla apné på fyra år.
Vid utförande av klinisk forskning som det här exemplet rekryteras vanligtvis en delmängd av befolkningen av intresse för att öka studieeffektiviteten (mindre kostnader och mindre tid).
Denna undergrupp av individer, den studerade befolkningen, består av de som uppfyller kriterierna för integration och är överens om att delta i studien, vilket framgår av bilden nedan.

Därefter avslutas studien och en effektstorlek (till exempel en medelskillnad eller relativ risk ) beräknas för att svara på forskningsfrågan.
Denna process, som kallas inferens, innefattar användningen av data som samlats in från studiepopulationen för att uppskatta storleken på den faktiska effekten på populationen av intresse, det vill säga ursprungsbefolkningen.
I det givna exemplet rekryterade forskarna ett slumpmässigt urval av statliga anställda (källpopulation) som var berättigade och godkände att delta i studien (studiepopulationen) och rapporterade att astma ökar risken för att utveckla apné i studiepopulationen.
För att ta hänsyn till ett provtagningsfel på grund av rekryteringen av enbart en undergrupp av intressebolaget beräknade de också ett 95% konfidensintervall (runt uppskattningen) på 1, 06 - 1, 82, vilket indikerar sannolikheten för 95 % att den sanna relativa risken i källpopulationen skulle ligga mellan 1, 06 och 1, 82 .
Förtroendeintervall för medelvärde
När man har information om standardavvikelsen hos en population kan man beräkna ett konfidensintervall för medeltalet eller medeltalet av den populationen.
När en statistisk egenskap som mäts (såsom inkomst, IQ, pris, höjd, kvantitet eller vikt) är numerisk, uppskattas i de flesta fall att medeltalet för befolkningen hittas.
Sålunda försöker vi hitta populationens medelvärde ( μ ) med hjälp av ett medelvärde ( x )), med en felmarginal. Resultatet av denna beräkning kallas förtroendeintervallet för populationens medelvärde .
När populationsstandardavvikelsen är känd är formeln för ett konfidensintervall (CI) för ett populationsmedel:

där:
- xiod är provvärdet;
- σ är populationens standardavvikelse;
- n är provstorleken;
- Ζ * representerar det lämpliga värdet av normal normalfördelning för önskad konfidensnivå.
Följande är värdena för de olika konfidensnivåerna ( Ζ * ):
| Förtroende | Värdet av Z * - |
|---|---|
| 80% | 01:28 |
| 90% | 1.645 (konventionell) |
| 95% | 1, 96 |
| 98% | 02:33 |
| 99% | 02:58 |
Tabellen ovan visar z * -värden för de konfidensnivåer som tillhandahålls. Observera att dessa värden erhålls från normal normalfördelning (Z-).
Området mellan varje z * -värde och det negativa av detta värde är den (ungefärliga) konfidensprocenten. Till exempel är området mellan z * = 1, 28 och z = -1, 28 ungefär 0, 80. Därför kan denna tabell också utökas till andra förtroendeprocenter. Tabellen visar bara de mest använda procentandelarna av förtroende.
Se även meningen med hypotesen.


